ある特徴的な文字列がある。
11b484b6-cfeb-4730-8fba-467aee2d26ad
使ったことがあれば、恐らくすぐに UUID であると分かると思う。UUID は16進数がハイフンで分けられた特徴的なフォーマットをしている。その区切り方は、 8-4-4-4-12 となんだか不思議な感じだ。
そもそも、UUID は 128bit の数値であり、それを文字列で表現したものなのでハイフンが無くたって問題ない。にもかかわらずわざわざ覚えにくいケタで区切ることが多い。
その理由として、最初に思いつくのは人間が読みやすくするためだとは思うが、覚えやすく均等に区切ったり、左右対称の形にはできなかったのだろうか?
UUID の定義
UUID は RFC4122 で以下のように定義されている。因みにあまり推奨はされないらしいが大文字も許容されているらしい(知らなかった)。
UUID = time-low "-" time-mid "-"
time-high-and-version "-"
clock-seq-and-reserved
clock-seq-low "-" node
time-low = 4hexOctet
time-mid = 2hexOctet
time-high-and-version = 2hexOctet
clock-seq-and-reserved = hexOctet
clock-seq-low = hexOctet
node = 6hexOctet
hexOctet = hexDigit hexDigit
hexDigit =
"0" / "1" / "2" / "3" / "4" / "5" / "6" / "7" / "8" / "9" /
"a" / "b" / "c" / "d" / "e" / "f" /
"A" / "B" / "C" / "D" / "E" / "F"
命名は UUIDv1 に完全に対応している。UUIDv1 ではザックリ以下のような値が入る。(ビットオーダーはビッグエンディアン)
- 青色: 100ns 精度の生成時刻(
1582-10-15 00:00:00+00:00からの経過時間) - 赤色: UUID のバージョン。UUIDv1 の場合は 0x1 になる
- 黄色: バリアント。 RFC4122 で定義された形式は 0b10 で固定されている
- 緑色: 生成のたびに増加するシーケンス番号で、100ns 以内に2つ以上UUIDが生成されたり時間が過去に設定されるなどした際の重複の確率を減らすためのもの
- 紫色: UUID を生成した機器のを識別するもので、MACアドレスが使われる。取得できない場合は乱数を使用する 1
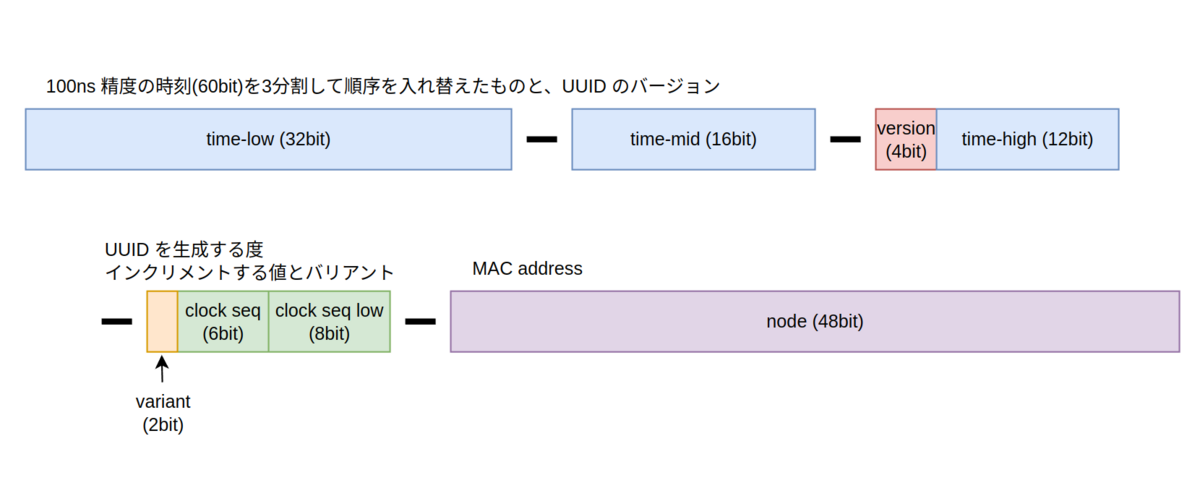
因みによく使われる UUIDv4 はバリアントとバージョン(赤、黄色)の部分以外がランダムに生成されている。
UUIDv1 は python だと以下のように生成できる。このモジュールではシーケンス番号は渡してあげる必要がある(渡さない場合は乱数が使われる)。
import uuid
uuid.uuid1()
生成した UUIDv1 を眺めてみる
上で説明した内容が正しいことを確認するために、軽く検証をしてみる。 1s (= 1,000,000ns)の sleep を入れてシーケンス番号を0から増やしながら生成した。
import time import datetime import uuid print(datetime.datetime.now()) # 2023-06-18 20:00:05.535037 print(uuid.uuid1(clock_seq=0)) # 4828cd80-0dc7-11ee-8000-1ff59d5c9f69 time.sleep(1) print(datetime.datetime.now()) # 2023-06-18 20:00:06.536212 print(uuid.uuid1(clock_seq=1)) # 48c192cb-0dc7-11ee-8001-1ff59d5c9f69 time.sleep(1) print(datetime.datetime.now()) # 2023-06-18 20:00:07.537512 print(uuid.uuid1(clock_seq=2)) # 495a5c37-0dc7-11ee-8002-1ff59d5c9f69
まず、一番最後の node セグメントは生成したホストを識別するものであるためすべて 1ff59d5c9f69 である。先頭が 1 であり乱数で生成したものだということが分かる。(注釈1を参照)
最後から2番目のセグメントは渡したシーケンス番号が使われていて 8000, 8001, 8002 とインクリメントされた値になっている。最初が 8 なのは先頭のビットがバリアント 0b10であるためだ。
最初の3セグメントは生成時刻が使われているが、そのうち違いが出たのは一番最初のセグメントだけだった。以下の表に各セグメントがインクリメントされる頻度を計算した数字を記載したが。2,3番目のセグメントが変化しなかったのはそれぞれ 約430 s, 約326 days 経過しないと変化しないためである。
| セグメント | インクリメントされる頻度 |
|---|---|
| time-low | 100 ns 毎 |
| time-mid | 約430 s 毎 2 |
| time-hi | 約326 days 毎 3 |
先頭のセグメント time-low を比べてみる。1s (= 10,000,000ns)の sleep を入れていれたので大体1千万ずつ増えていて、想定通りだ。
| time-low の値 | 10進数表記 |
|---|---|
| 4828cd80 | 1,210,633,600 |
| 48c192cb | 1,220,645,579 |
| 495a5c37 | 1,230,658,615 |
元祖 UUID(Network Computer System の UUID)
ところで、UUID が初めて使われたのは Apollo Computer 社の Network Computer System (以後 NCS と書く)である。4 このときの UUID の形式は以下のようになっていて、前述の UUIDv1 と非常に似ている。RFC4122 と比較してみると 「reserved / address family」 が 「version / variant」 に圧縮され、Host の識別コードのサイズが小さくなり、空いた空間を timestamp や clock sequence に割り当てたように見える。

形式の謎
これまで説明したように、8-4-4-4-12 なのは RFC 4122 で定義されているからである.....というのは確かにそうなんだろう。 定義を見れば、最後の2セグメントは納得した。
しかし、timestamp の部分をわざわざ 8-4-4 の 3セグメントに分割したのはなぜか?という新しい疑問が生まれてしまった。
前項の NCS の UUID では timestamp は分割もされていなければ、順序も自然である。一方で RFC4122 の定義では time-low time-mid time-hi と分割した上で順番を逆にしている。もし、RFC4122 の timestamp が自然に並んでいたとすれば、16-4-12 と区切られていたかもしれない。
そうなっていない理由を調べまくってみたものの、ソースと言えるような情報が見つからなかったのでここから先は予想の割合が多くなる、と予め断っておく。
RFC4122 で timestamp を3分割して順番を入れ替えたのはなぜだろう?
結論を先にいうと、timestamp をわざわざ分割して順序を入れ替えた理由として尤もらしいのは、検索効率を高めるため かなと思う。
UUID は 128bit の値であるが、多くのコンピューターでは一度に扱えるのは 32~64 bit までである。そのため UUID の比較は一度では完結しない。文字列形式で比較する場合はハイフンを含めると36回の比較が必要となる。
自然に実装された比較用の関数では恐らく前から比較を繰り返すはずである。もし、timestamp が自然に並んでいる場合最上位ビットから比較をしていくことになる。(以下の図では簡単のため version 部分を無視している)
その場合、一番最初に比較することになるであろう bit は 1827年間もの間変化が起きない。もしあなたがヴァンパイアでもなければ生きている内に更新されることはほとんど無い。つまりめったに変わらない値を無駄に比較する計算コストが毎回発生してしまう。

これは、頻繁に変化する部分から比較していくことで改善できる。下位のビットを前に持ってくるだけで一番最初に比較する bit の更新頻度が約215秒まで短くなる。よって、異なる UUID 同士を比較する際、はじめに見た部分が重複している確率が低くなる(カーディナリティが高くなる)ため「一致しない」と判断できる時間が平均で短くなる。
また、ビットオーダーがビックエンディアンであるため、計算効率を考えると2分割するよりも3分割するほうが効率が良い。
つまり、timestamp を3分割し、更に順番を入れ替えたのは計算コスト的なメリットがあるためではないだろうか。

更に、ほとんどの CPU では 32bit の値同士の比較は一発で完結する。timestamp の下位 32bit を time-low として定義し、先頭に配置することで計算効率が最大化できるはずだ。
そう考えると、8-4-4-12 と区切るのはそこまで不思議には見えなくなりませんか??

比較速度の実験
前項で UUID の timestamp が3セグメントに区切られているのは、比較演算の効率が良くなるからではないかという仮説を挙げた。実際に比較速度に差が出るのかを試してみる。
そのために以下のような関数を作成してみた。やっていることは単純に、UUIDv1 の timestamp 部分を入れ替えて形式を整えているだけである。
import uuid def timestamp_sorted(uuid1): split_uuid = str(uuid1).split("-") joined_uuid = f"{split_uuid[2]}{split_uuid[1]}{split_uuid[0]}{split_uuid[3]}{split_uuid[4]}" # timestamp 部分の順番を入れ替える hyphen_separated = f"{joined_uuid[:8]}-{joined_uuid[8:12]}-{joined_uuid[12:16]}-{joined_uuid[16:20]}-{joined_uuid[20:]}" # 8-4-4-12 に区切り直す return uuid.UUID(hyphen_separated) uuid1 = uuid.uuid1() print(uuid1) # 57f5eda8-0de2-11ee-9592-1ff59d5c9f69 print(timestamp_sorted(uuid1)) # 11ee0de2-57f5-eda8-9592-1ff59d5c9f69
計測結果
普通の UUIDv1 と先程の関数を使って timestamp 部分を入れ替えた UUID をそれぞれ用意し、「str型」「int型」にキャストした。それを in 演算子で存在を確認しそれにかかる時間を計測した。
計測コードや実行環境はこちら
import uuid import time def timestamp_sorted(uuid1): split_uuid = str(uuid1).split("-") joined_uuid = f"{split_uuid[2]}{split_uuid[1]}{split_uuid[0]}{split_uuid[3]}{split_uuid[4]}" # timestamp 部分の順番を入れ替える hyphen_separated = f"{joined_uuid[:8]}-{joined_uuid[8:12]}-{joined_uuid[12:16]}-{joined_uuid[16:20]}-{joined_uuid[20:]}" # 8-4-4-12 に区切り直す return uuid.UUID(hyphen_separated) for N in [10_000, 20_000, 40_000, 80_000]: # UUID 型 original_uuids = [] for i in range(N): original_uuids.append(uuid.uuid1(clock_seq=i)) timestamp_sorted_uuids = [] for uuid1 in original_uuids: timestamp_sorted_uuids.append(timestamp_sorted(uuid1)) # 公平にするために同じ UUID を使う # str 型 original_str_uuids = [str(i) for i in original_uuids] timestamp_sorted_str_uuids = [str(i) for i in timestamp_sorted_uuids] # int 型 original_int_uuids = [i.int for i in original_uuids] timestamp_sorted_int_uuids = [i.int for i in timestamp_sorted_uuids] # 比較速度を計測 print(f"\nN={N}") st = time.time() for target in original_str_uuids: assert target in original_str_uuids print(f"(1) original_str_uuids: {time.time() - st}") st = time.time() for target in timestamp_sorted_str_uuids: assert target in timestamp_sorted_str_uuids print(f"(2) timestamp_sorted_str_uuids: {time.time() - st}") st = time.time() for target in original_int_uuids: assert target in original_int_uuids print(f"(3) original_int_uuids: {time.time() - st}") st = time.time() for target in timestamp_sorted_int_uuids: assert target in timestamp_sorted_int_uuids print(f"(4) timestamp_sorted_int_uuids: {time.time() - st}") st = time.time() for target in original_uuids: assert target in original_uuids print(f"(5) original_uuids: {time.time() - st}") st = time.time() for target in timestamp_sorted_uuids: assert target in timestamp_sorted_uuids print(f"(6) timestamp_sorted_uuids: {time.time() - st}") """ # 実行環境 - CPU: Ryzen 5 3600 - RAM: DDR4 2666Mhz 16GB * 4 # 結果 N=10000 (1) original_str_uuids: 0.3417835235595703 (2) timestamp_sorted_str_uuids: 0.3435380458831787 (3) original_int_uuids: 0.22490262985229492 (4) timestamp_sorted_int_uuids: 0.24231791496276855 (5) original_uuids: 3.326829671859741 (6) timestamp_sorted_uuids: 3.4304888248443604 N=20000 (1) original_str_uuids: 1.3766262531280518 (2) timestamp_sorted_str_uuids: 1.414670705795288 (3) original_int_uuids: 0.9101331233978271 (4) timestamp_sorted_int_uuids: 0.971062421798706 (5) original_uuids: 13.154400110244751 (6) timestamp_sorted_uuids: 13.526567697525024 N=40000 (1) original_str_uuids: 5.531908750534058 (2) timestamp_sorted_str_uuids: 5.541355133056641 (3) original_int_uuids: 3.6439473628997803 (4) timestamp_sorted_int_uuids: 3.8880937099456787 (5) original_uuids: 52.94257402420044 (6) timestamp_sorted_uuids: 53.115707874298096 N=80000 (1) original_str_uuids: 22.447378873825073 (2) timestamp_sorted_str_uuids: 22.161968231201172 (3) original_int_uuids: 14.249858140945435 (4) timestamp_sorted_int_uuids: 15.570267915725708 (5) original_uuids: 210.6411235332489 (6) timestamp_sorted_uuids: 213.35009026527405 """
実験の結果、やはり全体的に通常のUUID v1(RFC4122 準拠)の方が比較が速かった(比率がマイナス = RFC4122形式での比較の方が速い)。特に int 型では顕著に差が出た。
str 型と uuid 型では比較回数を増やしていくと差が縮まった。ループ回数を増やしたことで python 特有のオーバーヘッドが大きくなったからだと考えられそう。
結論としては、UUID のフォーマットが 8-4-4-4-12 と不思議な形になった理由には検索効率を高めるための工夫が隠れていたと考えるのは、そこまで見当違いでもないと思う。
uuid 型
| N | 通常の UUID | timestamp 部分を入れ替えた UUID | 比率 |
|---|---|---|---|
| 10,000 | 3.33 | 3.43 | -3.12% |
| 20,000 | 13.2 | 13.5 | -2.83% |
| 40,000 | 52.9 | 53.1 | -0.33% |
| 80,000 | 210.6 | 213.4 | -1.29% |
str 型
| N | 通常の UUID | timestamp 部分を入れ替えた UUID | 比率 |
|---|---|---|---|
| 10,000 | 0.342 | 0.344 | -0.51% |
| 20,000 | 1.38 | 1.41 | -2.76% |
| 40,000 | 5.53 | 5.54 | -0.17% |
| 80,000 | 22.4 | 22.2 | 1.27% |
int 型
| N | 通常の UUID | timestamp 部分を入れ替えた UUID | 比率 |
|---|---|---|---|
| 10,000 | 0.225 | 0.242 | -7.74% |
| 20,000 | 0.910 | 0.971 | -6.69% |
| 40,000 | 3.64 | 3.89 | -6.70% |
| 80,000 | 14.2 | 15.6 | -9.27% |
※経過時間の単位は秒