※細かく調べたり検証を行ったわけではないので、話半分に見てください
以下の記事で疑似乱数(xorshift)について考えていた時にある疑問が浮かんだので、それについて書いてみる。
buri83.hateblo.jp
実験のしやすさのため、周期が 216 - 1 の xorshift を準備する。このアルゴリズムで乱数を生成するときは内部状態 xs にゴニョゴニョと操作をしたものを返す。そしてその出力はそのまま次の内部状態になる。
当然だが xs が同じ場合、生成される乱数は同じになる。
unsigned short xs = 17;
unsigned short xor16(){
xs ^= xs << 7;
xs ^= xs >> 9;
xs ^= xs << 8;
return xs;
}
つまり、例えば 1 --> 4 --> 2 と一度出てきた疑似乱数アルゴリズムでは、1 --> 3 や 4 --> 5 の並びは存在しない 。1 の次は必ず 4 だし、その次は絶対 2 が出てくる。何度乱数を作っても 1 の次に 3 が出ることはない。雑に言うと順番がゴチャゴチャなカウンタみたいだ...。さらに、これは seed (内部状態の初期値)がいくら変わったところで生成される値の順番は変わらないということも言えそう。

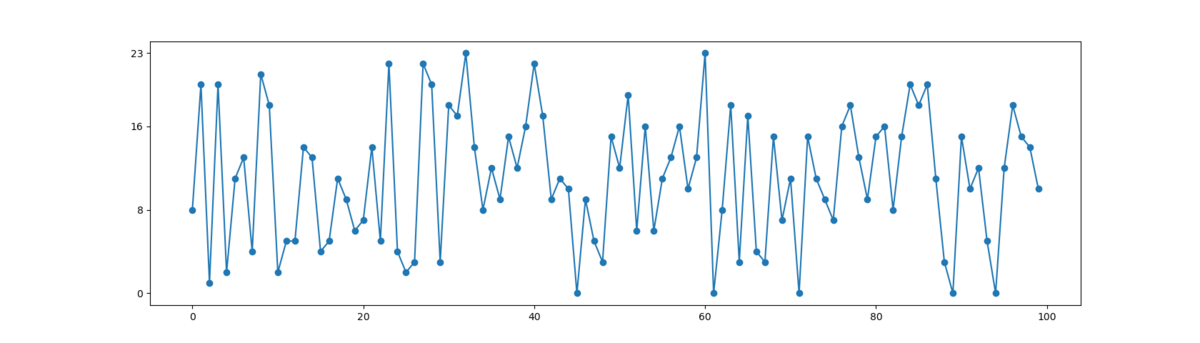
このようなプログラムで検証もしてみた。周期(同じ値が出るまでの生成回数)は 65,535 で「0」は一度も現れなかった。0 は何度シフトしても 0 なので当然だろう。なので、このアルゴリズムの周期は 216 - 1 ということになる。(疑似乱数の周期でよく 2n -1 になるのは、出ない値が存在するからなのかな?)
#include <stdio.h>
unsigned short xs = 17;
unsigned short xor16(){
xs ^= xs << 7;
xs ^= xs >> 9;
xs ^= xs << 8;
return xs;
}
int main(void){
unsigned short res[65536];
for(int i=0; i<65536; i++) res[i] = 0;
int r = 0;
for(int i=0; i<65536; i++){
r = xor16();
if (res[r] != 0){
printf("Duplicate !! r=%d res[r]=%d i=%d\n", r, res[r], i);
}
res[r]++;
}
printf("res[0]=%d\n", res[0]);
}
出てくる値が無秩序だったとしても、「生成した約6.5万個の乱数の中に重複した値は存在しない」というのは乱数としては違和感があるなぁ。
内部状態と出力を異なる bit 数にしてみる
先程の xor16() は内部状態が 16bit で、生成する値も 16bit だった。これでは1周期中に同じ値はでなさそう。
内部状態は 16bit のまま、生成する値が 8bit (内部状態よりも小さい)になると、1周期中に 28 (216 / 28 で) くらいは同じ値が登場するんじゃないか?という気がするので試してみる。
#include <stdio.h>
unsigned short xs = 17;
unsigned char xor8(){
xs ^= xs << 7;
xs ^= xs >> 9;
xs ^= xs << 8;
return xs & 0x00ff;
}
int main(void){
unsigned int res[256];
for(int i=0; i<256; i++) res[i] = 0;
unsigned char r = 0;
for(int i=0; i<65535; i++){
r = xor8();
res[r]++;
}
for(int i=0; i<256; i++){
printf("res[%d]=%d\n", i, res[i]);
}
}
予想通り、1周期中に 256回( 28 回)同じ値が出るようになった。res[0] が少ないのは「0」が出ないからだろうだが、もともとは 0 は一度も出なかったことを考えると偏りは改善されているとも言えそう。
また、最初の xor16() では 216 回生成した時に重複することはなかったが、xor8() では部分的に偏りができた。以下は 256 回生成した結果だが、「144」は 5 回もでているし、逆に「3」は 1 回も現れていない。
149, 62, 69, 205, 16, 65, 224, 201, 54, 95, 142, 251, 13, 190, 189, 15, 185, 125, 216, 231, 18, 42, 13, 175, 49, 251, 114, 30, 122, 125, 155, 22, 85, 233, 27, 162, 226, 171, 93, 210, 192, 130, 161, 122, 2, 59, 209, 39, 203, 112, 47, 236, 162, 213, 61, 196, 238, 136, 200, 158, 224, 214, 190, 230, 244, 225, 60, 112, 24, 122, 59, 233, 117, 142, 209, 18, 28, 27, 215, 5, 148, 170, 171, 21, 228, 158, 204, 203, 91, 176, 175, 12, 42, 19, 167, 105, 137, 79, 189, 62, 45, 163, 20, 44, 9, 234, 134, 136, 160, 176, 148, 159, 124, 126, 28, 119, 250, 180, 205, 97, 165, 26, 46, 70, 28, 15, 152, 165, 99, 204, 182, 186, 133, 25, 143, 61, 222, 165, 101, 142, 129, 110, 45, 243, 40, 109, 197, 62, 85, 129, 117, 166, 143, 66, 126, 98, 23, 172, 234, 227, 35, 250, 160, 130, 193, 82, 124, 51, 233, 125, 136, 219, 83, 230, 217, 124, 56, 46, 100, 5, 167, 127, 135, 29, 142, 249, 76, 76, 121, 174, 197, 61, 212, 226, 157, 11, 218, 208, 198, 194, 151, 44, 74, 91, 177, 111, 157, 6, 31, 142, 187, 61, 234, 178, 159, 90, 100, 113, 128, 209, 92, 104, 114, 77, 199, 95, 191, 111, 211, 114, 118, 20, 121, 246, 255, 118, 89, 204, 140, 169, 50, 124, 19, 177, 39, 171, 88, 81, 228, 154, 143, 126, 111, 146, 130, 179,
当然、216 - 1 という周期があるので周期性がなくなったわけではないが、1通りの乱数列から256通りの乱数列になり、より乱数っぽさは増した気がする。
このような使い方が最適なのかは良くわからないが、「内部状態」と「出力」の bit 数を変えていることはよく見かける。JavaScript (V8)の Math.random() は以下のようになっているらしい(There’s Math.random(), and then there’s Math.random() · V8)。
uint64_t state0 = 1;
uint64_t state1 = 2;
uint64_t xorshift128plus() {
uint64_t s1 = state0;
uint64_t s0 = state1;
state0 = s0;
s1 ^= s1 << 23;
s1 ^= s1 >> 17;
s1 ^= s0;
s1 ^= s0 >> 26;
state1 = s1;
return state0 + state1;
}
こちらは 128bit(64bit * 2)の内部状態をもっており、関数の出力は 64bit になっている。これにより、この2つの問題をマシにしているかもしれない。
- 0 が出ない問題
- ある値の次に出てくる乱数が固定になってしまう問題
また、周期が長いといえばメルセンヌ・ツイスタがあるが、ある程度の bit 数を出力したい & ランダムのバリエーションを増やしたいというニーズがあって作られたのかなと思った。しらんけど。(他にもメリットは沢山あるはず)
いろいろ考えてみたが正直な所、こういう乱数とかの細かい問題について、Amazon で本を調べても出てこなかったり、ググり方が分からないので実際どうなのかは分からないまま...
おわり。


")













")


")